<![CDATA[Cuttlepress]]>2014-01-01T19:34:02-05:00http://instamatique.com/hackerschool/Octopress<![CDATA[Not Graduating]]>2014-01-01T17:00:00-05:00http://instamatique.com/hackerschool/blog/2014/01/01/not-graduatingMy time at Hacker School is over. So, what have I learned?
Hacker School’s stated result for students is to become a “dramatically better” programmer, and I think I’ve been pretty successful in that direction. Here’s a partial list of things I can do now that I hadn’t done before September:
At the end of the recent Ludum Dare weekend, Lindsey asked me: “do you think you were better at LD as a result of having done HS?” To which I could only answer with, “Yes, definitely!” because there’s basically nothing in that game that I could have done three months ago (or at least, certainly not that quickly). I see my code skills as an important subset of my overall ability to Make Cool Things, and these new shiny tools in my toolbox will help me make different kinds of cool things than I’ve been able to make so far.
And, of course, I’ve talked to a whole bunch of new people. Without diminishing the splendor of 455 Broadway: the people are really the point of Hacker School, and they’re all utterly brilliant, with both a high degree of awesomeness and a willingness to share that awesomeness freely. I’m very fortunate to have been able to spend three months with the HS facilitators, residents, and my fellow students, and I look forward to continuing the many friendships and hopefully even some of the collaborations that began for me at Hacker School.
It just started being 2014 today. For the first couple of weeks of January, I’ll be working on housework and personal projects and visiting my family in California; as soon as I get back to Pittsburgh after that, I’ll be delighted/terrified/delighted to begin my approximately 2.5-month residency at the STUDIO for Creative Inquiry, Carnegie Mellon’s “laboratory for atypical, anti-disciplinary, and inter-institutional research at the intersections of arts, science, technology and culture.” I’m hoping to continue to blog regularly as part of that process, so stay tuned for details.
]]><![CDATA[Day 46]]>2013-12-20T04:00:00-05:00http://instamatique.com/hackerschool/blog/2013/12/20/day-46The end-of-batch party is still going, so: today I got teleportations working in my maps, and, with Adam, worked through a bunch of gotchas in the way one interacts with HTML forms via JavaScript. (For example: element.setAttribute(attributename, attribute) can’t be used to alter an existing atttribute; instead, you want element.attriutename = attribute. Similarly confusing is that, while readonly = true prevents an input element from being written to, readonly = false does not reverse the effect; you have to element.removeAttribute(attributename).
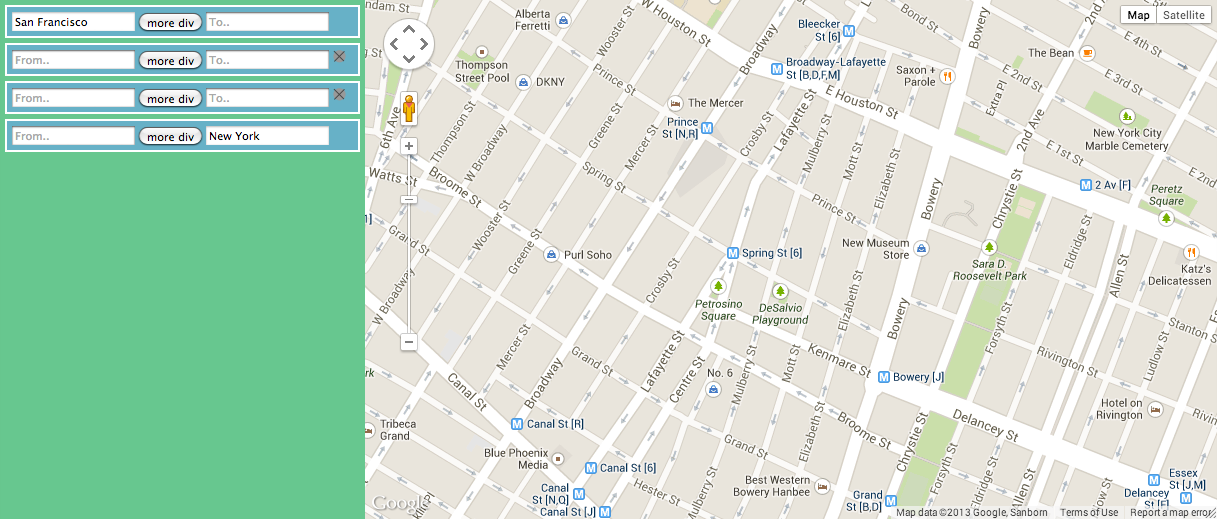
]]><![CDATA[Day 45]]>2013-12-18T23:04:00-05:00http://instamatique.com/hackerschool/blog/2013/12/18/day-45Even more messing about with maps today. I added the ability to add more steps to a journey (and remove them again!), and made the code more MVC-ish — it’s still very much a work in progress, though.
]]><![CDATA[Day 44]]>2013-12-17T18:43:00-05:00http://instamatique.com/hackerschool/blog/2013/12/17/day-44More work with Google Maps today. Arbitrary numbers of maps can now be added to the code, each with their own input devices and path renderers. In the afternoon, Mary helped me refactor the code for tidyness/modularity.
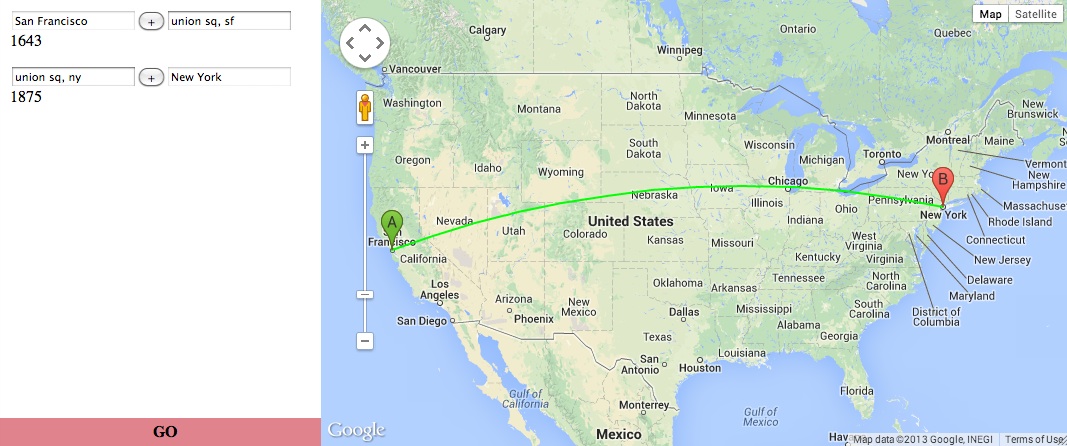
]]><![CDATA[Day 43]]>2013-12-16T22:26:00-05:00http://instamatique.com/hackerschool/blog/2013/12/16/day-43Spent today recovering a bit from Ludum Dare. I poked some more at the Ultimate Tic Tac Toe board with Fei very briefly, then moved on to learning about the Google Maps API. Jeff and I used the Directions API to get walking times between locations. It then turned out that Google prefers you not to use the data from the Directions API without displaying a map, so I also started looking at the more general-purpose Javascript API. Did you know there’s a fun widget for generating JSON to style Maps with?
]]><![CDATA[Project writeup: twitter heist]]>2013-12-16T13:01:00-05:00http://instamatique.com/hackerschool/blog/2013/12/16/project-writeup-twitter-heistThis weekend was Ludum Dare, the thrice-yearly 48-hour gamemaking competition, and the theme was “you only get one.” I liked the idea of enforcing just one playthrough per player, but not enough to implement cookies/IP detection/whatever else (and have those all be insufficient enforcement anyway), especially because other folks would almost certainly do that anyway. Then on the LD homepage, I saw in the embedded Twitter sidebar that folks were using “#YOGO” for their LD-related tweets, which I thought was hilarious. Since one of my goals for this LD was to showcase some of the skills I’ve learned at Hacker School, it was decided: I’d do some sort of game on Twitter.
Twitter text adventures are a thing I’ve thought about before, even to the extent of encouraging gwillen to make a Twitter interface to Parchment, and I definitely did not want to go to that length for this; I like to take Ludum Dare at a leisurely pace. I chatted with Sumana about various formats a Twitter game could take; for example, I could have a clearly-demarcated list of one- or two-letter commands that players could enter all in one tweet to play the game (like this but with a gameplay aspect). I also thought about single-move games, like Rematch. In the end, I decided to go with the simplest option: a choice-based game with one tweet per state change. I would prototype in Twine and store the game states in JSON.
Much of the tech is similar to that of Curated Dannel, in that I used ntwitter and mongodb. Incoming tweets are grabbed through a User Stream. The user id is checked against a database of player’s states, and the text is searched for words associated with a change from that state (as stored in game.json). The new state is looked up in another JSON file, and a response tweet is sent back to user. Properly threading the messages was one challenge, because although most API requests have matching “whatever_id” and “whatever_id_str” parameters (to handle the fact that many IDs on Twitter are too large for JS ints), there is no “in_reply_to_id_str” parameter on a request to the Twitter status update endpoint; you just have to use the “in_reply_to_id” parameter even though you’re sending a string id.
I didn’t get to the actual storytelling until Sunday afternoon, which I think is unfortunately very obvious in the game. I’d been batting around various ideas, but none seemed approachable in the amount of time I had. I ended up going with a very brief heist plot. (Did you know I love heiststories?) I tried to keep it goofy as a default fit with its context, because I didn’t have a lot of time to go beyond that.
Spoiler after the cut:
A couple of hours before deadline, I wanted to try to implement a response to a very open-ended request, such as a plea for a cookie recipe. Of course, I would need to do some automated checking as to whether or not the response was actually a cookie recipe, and I didn’t have a lot of time to implement it. Moshe helped me get started on requesting pages from within Node (just use the “request” module! it even handles redirects), and here’s my cookie-checking code:
varrequest=require("request");varcookieWords=["recipe","butter","sugar","eggs","vegan","flour","gluten","bake","heat","cook","ingredients"];functionverifyCookieRecipe(url,callback){request({url:url,followAllRedirects:true},function(error,response,body){if(!error){body=body.toLowerCase();cookieScore=0;for(vari=0;i<cookieWords.length;i++){if(body.search(cookieWords[i])>=0){cookieScore+=1;}}varnextstate="";if(cookieScore>=cookieWords.length/2){nextstate="cookie_success";}else{nextstate="cookie_failure";console.log(url,cookieScore);}if(callback&&typeofcallback==="function"){callback(nextstate);}}else{console.log("Couldn't get url");nextstate="cookie_failure";if(callback&&typeofcallback==="function"){callback(nextstate);}}});}
One last set of challenges was getting everything on AWS in a very short period of time — I’d put Curated Dannel on AWS, but it had required a lot of noodling around and poking at dependencies and such. Luckily, Kate was around to help me run through it. I got a couple of bug fixes in during “upload hour” (which is the buffer time LD gives people to get their games online after the 48 hours) and shortly thereafter (the later one was a “typo fix,” which is allowed by LD rules), and I think it’s stable now. Lindsey sent me my very first pull request, to fix a typo in some game text.
As a design note, the instantaneous responses from the game are a bit disconcerting, especially within the fiction. They also don’t play well with the slow refresh rate of most users’ Twitter clients. If I were reworking this, one thing I’d change would be to add some artificial delay.
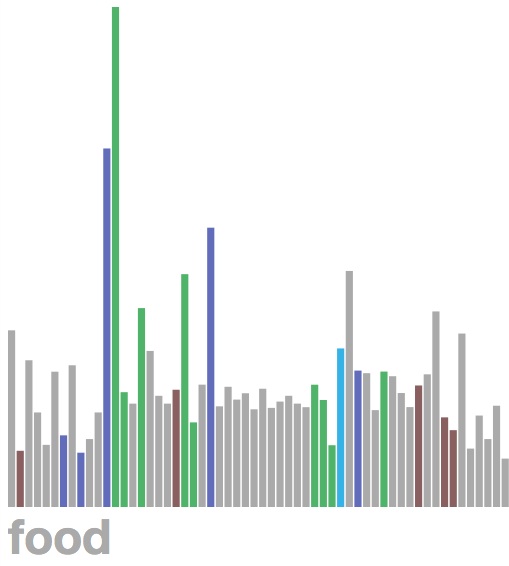
]]><![CDATA[Day 42]]>2013-12-12T23:07:00-05:00http://instamatique.com/hackerschool/blog/2013/12/12/day-42I went to Julia’s Unix executables presentation, and then I did a bit more poking at D3. My expenses chart now shows each expense’s category when it is hovered over:
Then I wanted to get back into the swing of JS/canvas stuff to warm up for this weekend’s Ludum Dare. Fei and I worked on a board for playing Ultimate Tic Tac Toe (implementing the base set of rules, but not yet the “clarifying rules” at that link):
]]><![CDATA[Day 41]]>2013-12-12T00:20:00-05:00http://instamatique.com/hackerschool/blog/2013/12/12/day-41Spent today mostly on other people’s projects. I had some great conversation with Katie about the structure of her interactive fiction engine. I’m very trained to the Inform 7 way of doing things, so it was a fun exercise to think about the strengths and weaknesses of the various parts of that system; of course, Katie’s project is a lot smaller in scope than Inform, so a lot of simplification is called for. I always love an opportunity to pull out the Inform 7 rules chart.
I also “helped” Lyndsey create a horrifying process hydra in supervisord. (You’d kill one process, and two would spring up!)
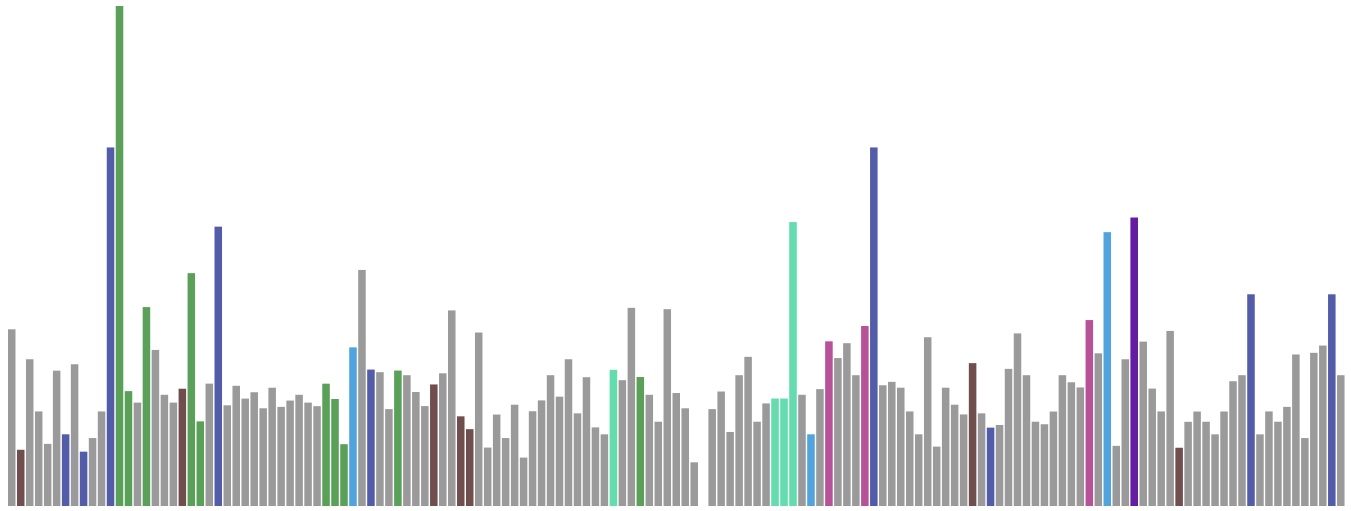
]]><![CDATA[Day 40]]>2013-12-10T23:39:00-05:00http://instamatique.com/hackerschool/blog/2013/12/10/day-40I started the day without a lot of direction, and Julia suggested that I take the day to learn D3. Good idea! I worked through this tutorial and generated this exponentially-scaled bar chart of all my monetary transactions (not including rent/utilities) while I’ve been in NY:
Here’s the entirety of the JavaScript (colors were styled in the CSS):
]]><![CDATA[Day 39]]>2013-12-09T22:48:00-05:00http://instamatique.com/hackerschool/blog/2013/12/09/day-39I added a server and some styling to get my infinite monkey trainer project to a fine stopping point for now, and threw some more Sass at Moshe’s “parannoyed” project. In the evening, there was an uproarious lecture by rØml on APL; very good show.
]]><![CDATA[Project writeup: infinite monkey trainer]]>2013-12-09T16:28:00-05:00http://instamatique.com/hackerschool/blog/2013/12/09/project-writeup-infinite-monkey-trainerThe Infinite Monkey Trainer is a project I’ve been backburnering on and off for years. The concept is a machine that will act as an operant conditioner for the infinite monkeys, to speed their production of Hamlet: when a participant enters text into the machine, the machine judges the text’s similarity to Hamlet and rewards bananas accordingly. In its final form, this will ideally be a physical installation, with an actual typewriter and a dispenser of banana candies, but I’ve been primarily concerned with the software up to this point.
An earlier iteration simply compared an incoming string, stripped of spaces and punctuation, to a string consisting of the entirety of Hamlet, similarly stripped. It was my first and only JS project before Hacker School, and an okay prototype. But the scoring was entirely binary, with no room for plausible phrases or misspellings.
Misspellings seemed important to me. After all, we’re talking about Shakespeare: it’s not like spelling was standardized. Earlier in Hacker School, I made a stab at working on the misspellings issue, by implemementing Metaphone. By Metaphoning the input string and the original text, I could ignore nonstandard spellings (or at least, nonstandard spellings that Metaphone to the same thing).
Last week, we had Alex Rudnick in residence, and he helped me progress much further. His suggestion was to implement a language model trained on Hamlet, and use that to check the “probability” of the incoming string’s existence in that text. This turned out to be less complicated than I’d thought. Once the bigrams and unigrams have been pulled out from the text (I’m storing them in JSON), I can simply do some dictionary lookups to grab the probabilities of individual bigrams and multiply them for the whole string. On Alex’s advice, I’m using “Stupid Backoff” when I fall back to an (n-1)gram, because it’s Good Enough. Here’s the lookup in total:
// Check the probability of an phrase, as an array of words.functioncheckProbability(text,bigrams,unigrams){varprev=text[0];varvalue=0;// if we have at least two words, we can check the bigramsif(text.length>1){for(vari=1;i<text.length;i++){current=text[i];if(previnbigrams&¤tinbigrams[prev]){value+=bigrams[prev][current];}elseif(currentinunigrams){value+=unigrams[current]+0.91629;// "stupid backoff" (Brants et al 2010) is we multiply the (n-1)grams value by 0.4// aka add the neglog of 0.4, which is 0.91629}else{value+=unigrams["LEAST_COMMON_PROB"]+0.91629;// and if it doesn't exist there, call it as common as the least comnon thing}prev=current;}}// otherwise, we can only check the word as a unigramelseif(text.length>0){if(previnunigrams){value+=unigrams[prev]+0.91629;// "stupid backoff" again}else{value+=unigrams["LEAST_COMMON_PROB"]+2*0.91629;// and if it doesn't exist there, stupid backoff to it being as common as the least comnon thing}}// otherwise, the value stays at 0, but then so does the text.lengthreturnvalue;}
One next step I’d like to take is reintegrate the spelling forgiveness. An easy thing to do would be to check both the original string against the original language model and the Metaphoned string against a Metaphoned language model. I’d also like to be more forgiving of common typos, such as adjacent keyboard keys; I suspect there are well-known best practices there.
Another work in progress is the function that converts the between the language model-based probability of a string and its worth in bananas. Currently, I’m using the scoring function I posted last week. I’m comfortable putting off betatesting until after Hacker School.
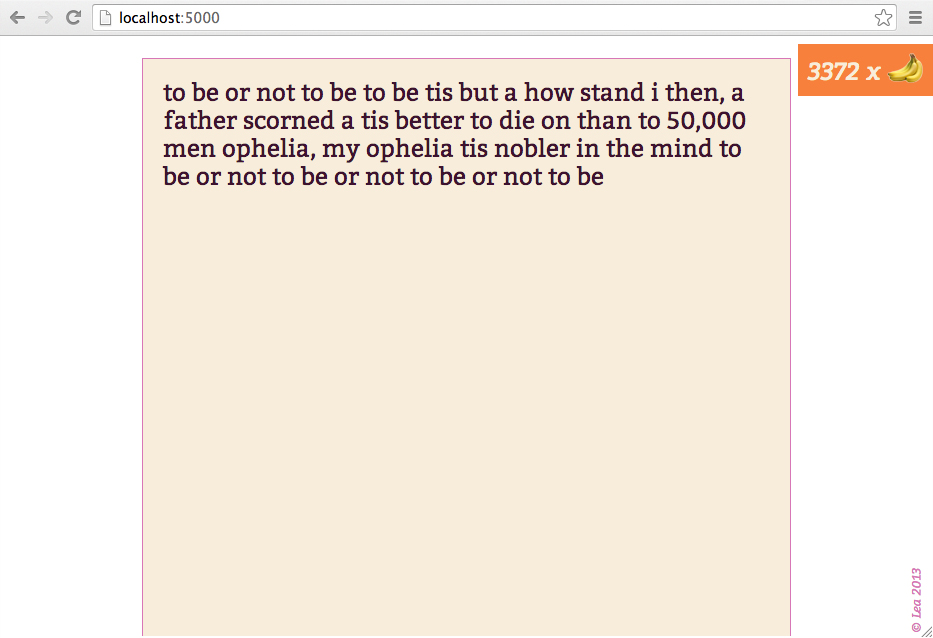
For presentability, I’ve wrapped the whole thing in an interactive webthing. For obfuscation, the similarity-to-Hamlet calculation is done server-side. The client and server communicate via Socket.io with code almost entirely ripped from my earlier picture chat project. There’s a bit of Sass-based CSS and an image of some bananas, as well. Here’s a screenshot:
]]><![CDATA[Day 38]]>2013-12-06T01:51:00-05:00http://instamatique.com/hackerschool/blog/2013/12/06/day-38A short day and a long one: I left the job fair after midnight, but the coding part of the day only ran until 3:30 to squeeze in Thursday presentations before the job fair. In the morning, I attended Alex’s livehacking Markov chains demo; we basically reimplemented the work I did yesterday, but in Python, and faster. The rest of the day, I worked on my goofy generative Inform 7 project. The results were trained on Emily Short’s Bronze and they are of course mostly not valid Inform, but some are evocatively close:
To decide whether melancholy or enslaved the player:
if the player
begin;
say "yourself";
rule succeeds;
end if;
Solving is a thing is scenery.
The stone bench is not unsolved.
Understand "bite [something enterable]" as attacking.
Understand "get [things preferably held] down" as dropping.
Carry out looking toward:
say "You can't enter [the noun]."
Instead of answering it is easier to you do this world to lit room is a long time: try dropping rule when novice mode on" as hunting.
Understand "solve [something]" as wearing.
Understand "search" as attacking.
The inkpot is that the gate.
I also tried a few approaches to separating out the Inform code from the game text and running the generators separately. More on this after a full night’s sleep.
]]><![CDATA[Day 37]]>2013-12-04T19:55:00-05:00http://instamatique.com/hackerschool/blog/2013/12/04/day-37For the first part of the day, I made the writeup post for the Twitter project.
I paired with Stephen on his Zulip bot, which generates text based on a given set of Zulip streams. We worked on cleaning the input of blocks of code, unencoding the HTML entities in the output, and making the input case-insensitive.
For my Hamlet project, I finished writing how to generate bigrams, added the function to tabulate the probability of the input string, and modularized my Metaphone code. I also put some thought into the question of how scoring works: players that type convincing phrases need to be rewarded accordingly. Scoring clearly needs to take the length of the text into account, because otherwise a single word from the corpus is going to score best. While this is the sort of thing that is best done with playtesting, here’s a first attempt at mapping a phrase’s probability value to a score (remember that the probabilities are as negative logarithms; that is, a lower number is a better score):
123456789101112
functioncalculateScore(text,value){varscore;if(text.length<1){score=0;}// longer strings with smaller "values" are worth more pointselse{varavgValue=value/text.length//going to be somewhere between 0 and 11.2score=Math.round(10*(11.5-avgValue)*text.length);}returnscore;}
I ran this on several input phrases, with and without Metaphoning everything. Output below the fold.
File read in: hamlet.txt
Text: whether tis nobler in the mind to suffer the slings and arrows of outrageous fortune
score: 1281
------------------
Text: whether tis nobler in the mend to sufer the slings and arrws of outrajs fortune
score: 900
------------------
Text: fourscore and seven years ago
score: 203
------------------
Text: strumpet
score: 9
------------------
Text: your orisons
score: 117
------------------
Text:
score: 2
------------------
Text: lets all go to elsinore
score: 363
------------------
Text: lets all go to switzerland
score: 309
------------------
Text: lets all go to
score: 307
------------------
Text: to be or not to be or not to be or not to be or not to be or not to be or not to be or not to be or not to be or not to be or not to be or not to be or not to be
score: 3887
------------------
Text: call me ahab
score: 208
------------------
Text: call me maybe
score: 208
------------------
Text: call me elsinore
score: 229
------------------
Text: call me fellow
score: 266
------------------
________Let's try it Metaphoned!________
Text: w0r ts nblr in 0 mnt t sfr 0 slnks ant arws of otrjs frtn
score: 1266
------------------
Text: w0r ts nblr in 0 mnt t sfr 0 slnks ant arws of otrjs frtn
score: 1266
------------------
Text: frskr ant sfn yrs ak
score: 214
------------------
Text: strmpt
score: 9
------------------
Text: yr orsns
score: 117
------------------
Text:
score: 2
------------------
Text: lts al k t elsnr
score: 360
------------------
Text: lts al k t swtsrlnt
score: 309
------------------
Text: lts al k t
score: 307
------------------
Text: t b or nt t b or nt t b or nt t b or nt t b or nt t b or nt t b or nt t b or nt t b or nt t b or nt t b or nt t b or nt t b
score: 3909
------------------
Text: kl m ahb
score: 208
------------------
Text: kl m mb
score: 208
------------------
Text: kl m elsnr
score: 229
------------------
Text: kl m flw
score: 261
------------------
As you can see, simply looping “to be or not to be or not to be [etc]” is a clear exploit. (Credit to Rishi.)
]]><![CDATA[Project writeup: curated twitter]]>2013-12-04T10:00:00-05:00http://instamatique.com/hackerschool/blog/2013/12/04/project-writeup-curated-twitter“Curated Dannel” is a project I’ve been joking about implementing for at least a year. While I would love to follow Dannel on Twitter, his tweeting frequency is a bit higher than what I can keep up with. I needed some way of curating his tweets. Luckily, Twitter has a couple of ways to vouch for the attention-worthiness of tweets: favorites and retweets. So, in theory, it’s easy to crowdsource.
I decided to use Node again for this project, and using ntwitter allowed me to interface with the Twitter API without dealing with any of the details of authenticating via OAuth. The API provides access to individual entities (such as existing tweets or users) through queries, and separately, access to realtime events (such as incoming tweets or favorites) through streams. Information is not necessarily consistent across the two, so a hybrid approach seems to be recommended. (One convoluted behavior I dealt with did turn out to be a bug, not a design decision, at least.)
After trying out many different approaches, I ended up with this method: I open an authenticated User Stream as Dannel, which allows me to see his incoming “favorite” and “retweet” events. If the event is on a tweet written by Dannel (his stream also sees events on other relevant tweets, such as further retweets of tweets he previously retweeted), I then check the current total number of favorites and retweets on the included tweet, via the Search API. I store the text, tweet ID, favorite count, and retweet count in a database at MongoHQ, using mongodb. If I haven’t previously retweeted that tweet, I check its eligibility, potentially retweeting it and marking it in the database as retweeted.
Determining a tweet’s eligibility for retweeting is simple:
I figure that a retweet should count for more than a favorite, because it’s a more public way of vouching for a tweet’s attention-worthiness. This cutoff seems to provide about as many tweets per day as I’d like; in an optimal universe, the code would adjust its metrics to provide tweets at an approximate quantity over time instead, but in this less-than-optimal universe, I am very ready to move on from this project.
I grabbed a public domain image to make the user icon of the account. (I also used a gratuitous Photoshop “art” filter, which made me inordinately happy.) Another possible extension of this project would be to automatically update its content based on Dannel’s current icon, since he changes them monthly.
The last step was to ensure that, ideally, I never have to think about keeping the code running. It’s hosted on a small Amazon Web Services instance, and theoretically it should happily run for a pretty long time, but I wanted to not have to deal with crashes or server reboots. I used supervisord to restart the code after any crashes, and a startup script to start supervisord after any reboots.
]]><![CDATA[Day 36]]>2013-12-03T21:56:00-05:00http://instamatique.com/hackerschool/blog/2013/12/03/day-36Busy day! I finally got my Twitter project fully working, with the final piece being that I want to set-it-and-forget-it on my AWS server, so I was determined to find some way of automatically restarting the process if it broke or if the server was restarted. Moshe helped with get supervisord set up, though we had a lot of trouble with getting the “program” part of the conf file working. Tom helped us determine that the solution was to use absolute paths for both Node itself and my .js file, like so:
I also followed this tutorial to make sure the supervisord process runs on machine startup. I’ll do a real announcement/linking to the project tomorrow, once I’m more sure that it’s stable.
I attended Lindsey’s talk on LVars and parallel computing, and I really enjoyed it. The talk and many of the questions lead to a lot of “oh so that’s what that means” moments for me, and like all of the best presentations, it made me interested in a thing I’d never even thought about before.
I had an ofice hour with Alex, which was also really great. We determined that a good approach to my “how do we define ‘similar to Hamlet?’” question would be to generate a language model of Hamlet and check incoming phrases against the probabilities contained therein. He walked me through the basics of how I could construct such a model (build up a dictionary of bigrams, along with their probabilities), along with some implementation tips (for example, store probabilities as a negative logprob). It was lot of very comprehensible information in a fairly short time, and it really felt like learning/progress were occurring. I wrote up the code for grabbing the unigram probabilities from Hamlet and got most of the way through the bigrams (with some debug help from Rishi). Here’s unigrams, where choppedtext is an array of all the words in the text:
functionmakeUnigrams(choppedtext){vardict={};varhighestscore=0;// count the occurences of each wordfor(vari=0;i<choppedtext.length;i++){if(choppedtext[i]indict){dict[choppedtext[i]]+=1;}else{dict[choppedtext[i]]=1;}}// then use that count to calculate the probability of each wordfor(varwordindict){varcount=dict[word];varunlikeliness=(-1)*(Math.log(count/choppedtext.length));// storing the numbers as "negative logarithmic probabilities" helps by // 1) ensuring no numbers too small for floats, and // 2) allowing us to add them instead of multiplyingdict[word]=unlikeliness;if(unlikeliness>highestscore){dict["LEAST_COMMON_PROB"]=unlikeliness;}// dict also stores the highest unlikeliness, // which can be assigned to words that aren't recognized at all}// and write it to the external filefs.writeFile(unigramsfile,JSON.stringify(dict,null,4),function(err){if(err){console.log(err);}else{console.log("Unigrams saved to "+unigramsfile);}});}
]]><![CDATA[Day 35]]>2013-12-02T18:06:00-05:00http://instamatique.com/hackerschool/blog/2013/12/02/day-35Over the weekend, I discovered that it is possible to get streamed “favorite” events from the Twitter API… as long as you’re logged in as that user. Luckily my friends seem to trust me (?), so I am now authenticating both as my own application and the account that I want to watch.
I figured out how to watch for favorite events (if (data.event == "favorite")) and retweet events (if(data.retweeted_status)), and how to update documents in a MongoDB using the Node mongodb wrapper (a convenient findAndModify with {"upsert":"true"}).
But my retweeter, which is supposed to retweet when an incoming favorite/retweet event directs its attention to a tweet with more than a certain number of retweets/favorites, was never firing. It turns out that the “favorite_count” I was seeing was incorrect. My best guess is that, unlike the identically-named field of a naked tweet object, the “favorite_count” value of a tweet delivered via a streamed “favorite” event is relative to the authenticated user, meaning, “how many times has this user favorited the tweet?” Which is almost useless, since a user can’t favorite or retweet more than once; if you’re seeing the message at all, the answer is “once.” (Except that it’s the value right before the event was sent, so the value is actually “0.”) So you have to do a search query on the returned tweet ID, which counts against your rate limit. I’m going to run it tonight and see if I get rate limited. If I do, I’ll just do all the counting in my own database, and hope my stream doesn’t cut out.
I also went to lunch with Lindsey, who is at Hacker School as a resident! And I attended Daphne’s concise and demystifying Makefile workshop.
]]><![CDATA[Day 34]]>2013-11-26T18:33:00-05:00http://instamatique.com/hackerschool/blog/2013/11/26/day-34More working on Twitter: I sent tweets and retweets from Node (after re-discovering that it is important to use the string version of a tweet’s id because there are so many tweets). I also did the necessary work to deploy to Heroku — Procfile and package.json and such — and set up another of Heroku’s MongoHQ databases before realizing that Heroku probably wasn’t actually the right thing for this project. I wanted to have a single, long-running process (that opens a stream and acts on incoming data, forever or something like it), but Heroku’s web processes go to sleep after an hour of inactivity. There are hacky ways to work around it, such as sending pings to keep the process awake, or having only a background worker instead of a web process, but they seemed inelegant. After asking around, I decided that the best way to proceed would be to use AWS, so I made a new MongoHQ database and started to set up my AWS [micro]instance.
]]><![CDATA[Day 33]]>2013-11-25T23:13:00-05:00http://instamatique.com/hackerschool/blog/2013/11/25/day-33Today started early with Tom’s workshop on deploying to Amazon EC2, where we all learned how to use a tiny subset of the dizzying array of AWServices. In the afternoon, I attended Mary’s refactoring/testing workshop; we learned about testing in general and a bit about testing on asynchronous systems. I paired with Ashton on refactoring a very small server and writing some tests for it. For the other snippets of the day, I continued to read about the Twitter API and the many possible Node modules for interacting with it. Right before it was time to leave for the Monday talk, I finally got a filter stream working with ntwitter and help from Paul. Here’s the relevent code, which is deceptively short, for opening a stream of a particular user, and attaching a handler to incoming data:
1234567891011121314151617
vartwit=newtwitter({consumer_key:keys.consumer_key,consumer_secret:keys.consumer_secret,access_token_key:keys.access_token_key,access_token_secret:keys.access_token_secret});vartofollow=//whoever you want to follow, as a user id (not screenname)twit.stream('statuses/filter',{follow:tofollow},function(stream){console.log("making a stream");stream.on('data',function(data){if(data.text){console.log(pluck(data,["text"]));}});});
The Monday lecture was an entertaining overview by Zane Lackey of some of the principles behind how he and his team handle security at Etsy.
]]><![CDATA[Day 32]]>2013-11-21T18:51:00-05:00http://instamatique.com/hackerschool/blog/2013/11/21/day-32I paired briefly with Sumana on some basic CSS, but fixing the lag problem on my picture chat project consumed most of my day. Kate had suggested that I try using a spritesheet to speed load time; I was skeptical that it would make that big of a difference (there aren’t that many icons yet), but I figured I’d give it a shot. But I still wanted to automate the creation of the spritesheet, since I intend to add more icons as I have the inclination to draw them. So I spent the morning and part of the afternoon running in small, frustrating circles around a small handful of poorly documented imagemagick Node modules, trying to get anything working.
At some point I finally realized that I was in fact getting an error message at load time — I hadn’t noticed it because it was buried in the logs by all the socket-connecting. I asked on Zulip and Anton pointed out that I’d probably forgotten to enable the Websocket ability on Heroku. Which, of course, I had. Fixing it removed the lag and any remaining resolve I had to get spriting working.
The arrow icon was Rishi’s idea, and a very good one.
]]><![CDATA[Day 31]]>2013-11-20T21:49:00-05:00http://instamatique.com/hackerschool/blog/2013/11/20/day-31Spent some time doing tweaks to my picture chat app, including better support for mobile:
(After hours, I also spent a bit of time drawing some new icons.)
And I deployed it to Heroku! But I think it’s not quite ready for a link here yet.
In the afternoon, I paired with Mary on learning about the Twitter API. I can now grab tweets using the REST API; tomorrow I’d like to mess with streaming.
 ]]>
]]>

{kind=link}