The Infinite Monkey Trainer is a project I’ve been backburnering on and off for years. The concept is a machine that will act as an operant conditioner for the infinite monkeys, to speed their production of Hamlet: when a participant enters text into the machine, the machine judges the text’s similarity to Hamlet and rewards bananas accordingly. In its final form, this will ideally be a physical installation, with an actual typewriter and a dispenser of banana candies, but I’ve been primarily concerned with the software up to this point.
An earlier iteration simply compared an incoming string, stripped of spaces and punctuation, to a string consisting of the entirety of Hamlet, similarly stripped. It was my first and only JS project before Hacker School, and an okay prototype. But the scoring was entirely binary, with no room for plausible phrases or misspellings.
Misspellings seemed important to me. After all, we’re talking about Shakespeare: it’s not like spelling was standardized. Earlier in Hacker School, I made a stab at working on the misspellings issue, by implemementing Metaphone. By Metaphoning the input string and the original text, I could ignore nonstandard spellings (or at least, nonstandard spellings that Metaphone to the same thing).
Last week, we had Alex Rudnick in residence, and he helped me progress much further. His suggestion was to implement a language model trained on Hamlet, and use that to check the “probability” of the incoming string’s existence in that text. This turned out to be less complicated than I’d thought. Once the bigrams and unigrams have been pulled out from the text (I’m storing them in JSON), I can simply do some dictionary lookups to grab the probabilities of individual bigrams and multiply them for the whole string. On Alex’s advice, I’m using “Stupid Backoff” when I fall back to an (n-1)gram, because it’s Good Enough. Here’s the lookup in total:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | |
One next step I’d like to take is reintegrate the spelling forgiveness. An easy thing to do would be to check both the original string against the original language model and the Metaphoned string against a Metaphoned language model. I’d also like to be more forgiving of common typos, such as adjacent keyboard keys; I suspect there are well-known best practices there.
Another work in progress is the function that converts the between the language model-based probability of a string and its worth in bananas. Currently, I’m using the scoring function I posted last week. I’m comfortable putting off betatesting until after Hacker School.
For presentability, I’ve wrapped the whole thing in an interactive webthing. For obfuscation, the similarity-to-Hamlet calculation is done server-side. The client and server communicate via Socket.io with code almost entirely ripped from my earlier picture chat project. There’s a bit of Sass-based CSS and an image of some bananas, as well. Here’s a screenshot:
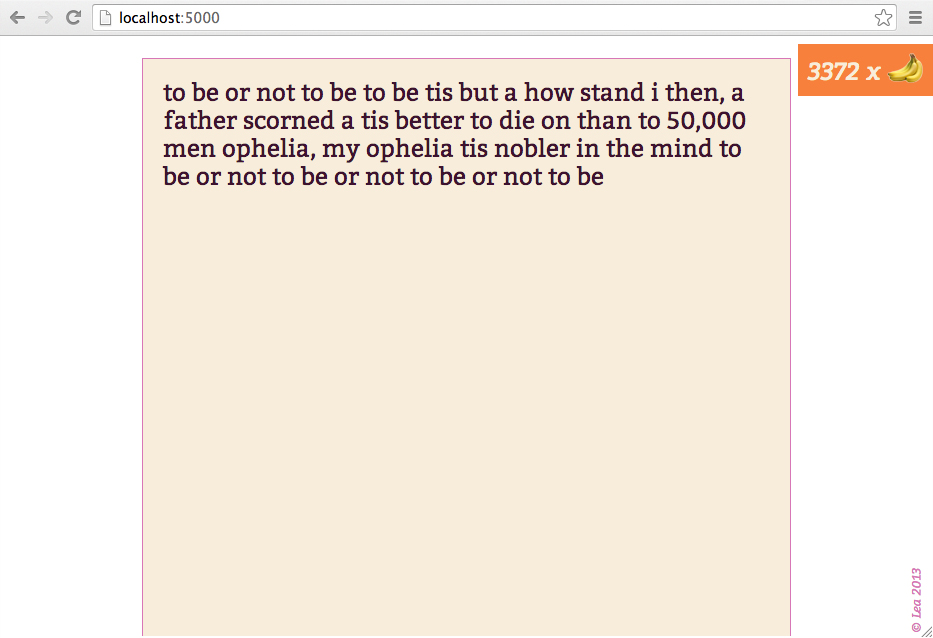
The code is on github. “Play” online at http://infinitemonkeytrainer.herokuapp.com/